吐槽一下市面上商业声音克隆软件高昂的订阅费、严苛的字数限制,以及将自己声纹数据上传到未知商业服务器的隐私泄露风险(比如声音被用来做诈骗电话或虚假广告)。
今天我们要用一个效果相当炸裂的开源模型(Step-Audio-EditX ),在 Google 提供的**免费安全云端(Colab)**上,搭建一个完全属于你自己的、无限字数、1:1 高仿你原声的在线声音克隆站。
1、你不需要懂任何 Python 或 Linux 命令行,只需复制下方这段我们精心调优的系统提示词,发送给 ChatGPT 或 Claude、Gemini 3.5或者其它主流,它就会自动为你写出完美运行的部署代码!
# 角色与任务:
你是一位资深的 AI 部署与运维专家,精通 Google Colab 环境配置、CUDA 驱动调试以及主流 TTS 声音克隆模型的部署。
请为我编写一套完整的 Google Colab 单元格部署脚本,用于在一台 Tesla T4 显卡(15GB 显存,系统默认 CUDA 12.x)的 Colab 实例上,完美部署并运行阶跃星辰开源的声音编辑与配音大模型项目 `Step-Audio-EditX`。
# 核心要求与步骤:
请将脚本分为 5 个清晰的代码块(对应 Colab 的 5 个 Cell),并附带中文注释说明。
## Cell 1:硬件检测
- 使用命令行查询并输出当前的 GPU 名称、总显存和剩余显存信息(使用 nvidia-smi 简洁格式)。
## Cell 2:克隆仓库与系统依赖初始化
- 切换工作目录到 `/content`;
- 克隆代码库:`https://github.com/stepfun-ai/Step-Audio-EditX.git`;
- 进入仓库目录 `/content/Step-Audio-EditX`;
- 安装快速包管理器 `uv`(使用 `-q` 静默安装);
- 使用 `uv sync --refresh` 同步项目依赖,这会自动创建虚拟环境 `/content/Step-Audio-EditX/.venv`;
- 使用 apt-get 安装系统音频处理依赖 `sox` 和 `libsox-fmt-all`(使用 `-q` 规避冗余日志)。
## Cell 3:多源模型下载(混合 HuggingFace 与 ModelScope)
- 创建并进入统一的模型目录 `/content/models`;
- 安装并启用 `git-lfs`;
- 使用 `git clone` 下载 HuggingFace 上的两个核心模型:
1. `https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer`
2. `https://huggingface.co/stepfun-ai/Step-Audio-EditX-AWQ-4bit`
- 注意 ASR 插件模型特殊路径:在 `Step-Audio-Tokenizer` 下创建子目录 `dengcunqin`。然后从 ModelScope 克隆 ASR 模型 `https://modelscope.cn/models/dengcunqin/speech_paraformer-large_asr_nat-zh-cantonese-en-16k-vocab8501-online.git` 到该子目录下。
## Cell 4:环境修复与兼容性重装(关键排错步骤)
由于 Colab 默认环境及 Numba 库存在严重的兼容性问题,必须在虚拟环境中执行以下强制修复:
1. 指定虚拟环境路径 `os.environ['UV_PROJECT_ENVIRONMENT'] = '/content/Step-Audio-EditX/.venv'`;
2. 修复 ONNX CUDA 驱动找不到的问题:使用 `uv pip` 强制在虚拟环境内重装适配 CUDA 12 的 `onnxruntime-gpu==1.20.1`,必须带上 `--python /content/Step-Audio-EditX/.venv/bin/python` 参数确保装在虚拟环境内;
3. 修复 Numba 不支持 NumPy 2.4+ 的报错(报错:ImportError: Numba needs NumPy 2.2 or less):使用 `uv pip` 强制将虚拟环境内的 `numpy` 降级安装为 `numpy==2.2.6`,同样指定虚拟环境的 python 路径。
4. 验证安装:使用虚拟环境的 python 导入 `onnxruntime` 和 `numpy` 并打印它们的版本,确保无报错。
## Cell 5:配置环境变量与低显存启动
1. 切换回 `/content/Step-Audio-EditX` 目录;
2. 规避 GUI 绘图错误,设置环境变量 `MPLBACKEND = 'Agg'`;
3. **极为重要**:必须将 CUDA 12.8 库路径 `/usr/local/cuda-12.8/targets/x86_64-linux/lib` 动态加入 `LD_LIBRARY_PATH` 环境变量,以便 `onnxruntime-gpu` 顺利调用显卡硬件;
4. 激活 `.venv` 虚拟环境,使用 python 运行 `app.py` 启动 Gradio 服务。
5. 必须传入以下适配 T4(15GB 显存)的启动参数:
- `--model-path /content/models/Step-Audio-EditX-AWQ-4bit`
- `--tokenizer-path /content/models/Step-Audio-Tokenizer`
- `--model-source local`
- `--gpu-memory-utilization 0.5`(严格限制显存比例)
- `--max-num-seqs 1`
- `--dtype float16` 且 `--cosyvoice-dtype float16`(半精度运行防止 OOM)
- `--no-cosyvoice-cuda-graph`(禁用 CosyVoice 的 CUDA 图,节省显存)
- `--enforce-eager`
- `--share`(生成外网可直接访问的 Gradio 共享链接)
# 输出格式要求:
请直接给出可以直接复制到 Colab 中运行的 Python/Bash 代码块,确保代码逻辑严密,注释详尽。
2、接下来到了部署环节,打开google colab新建笔记本
3,上传全自动部署脚本Step_Audio_EditX_Deploy.ipynb 这个脚本我放在Google dirve网盘,需要的可以下载。
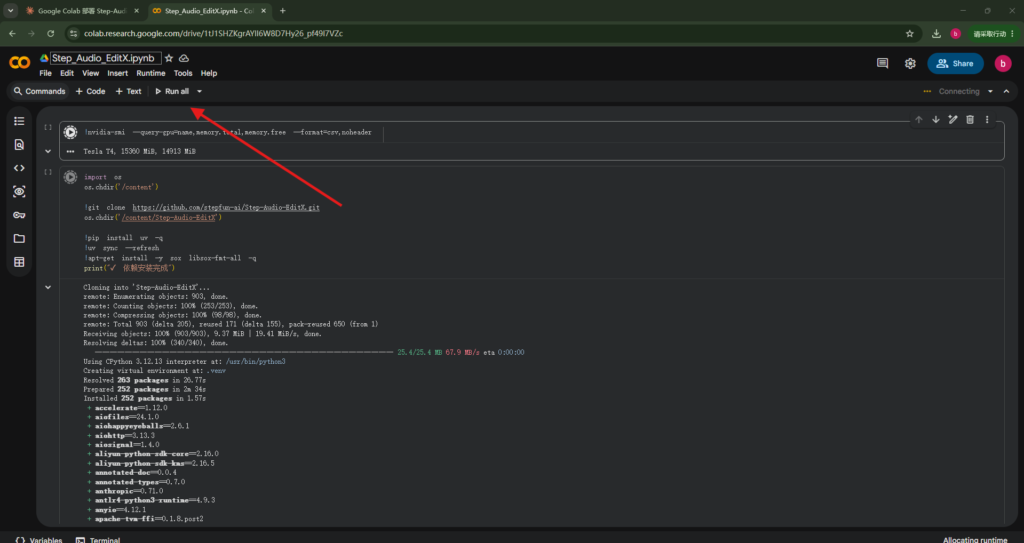
4、导入全自动部署脚本。点击run all,就可以自动完成全部任务。坐等最后给出的链接。
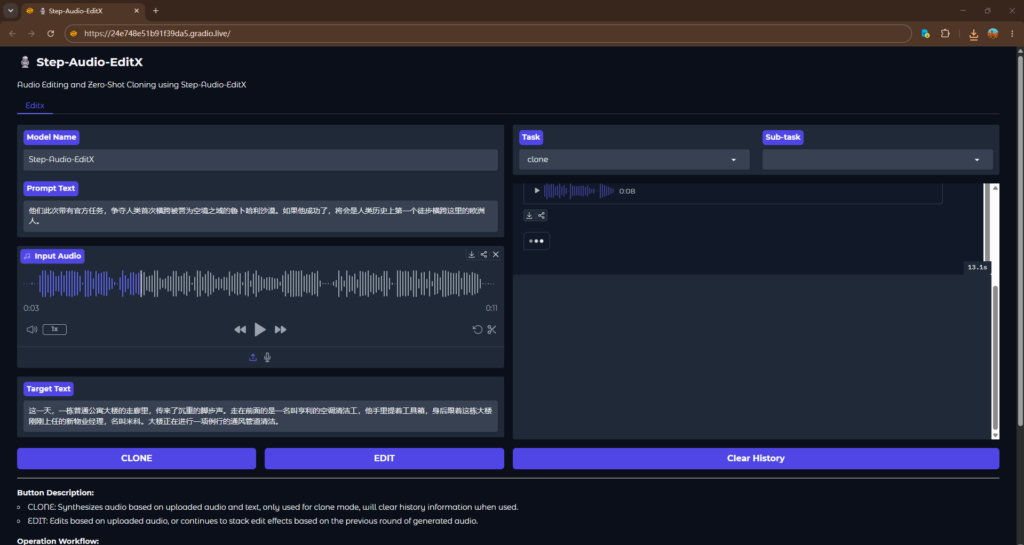
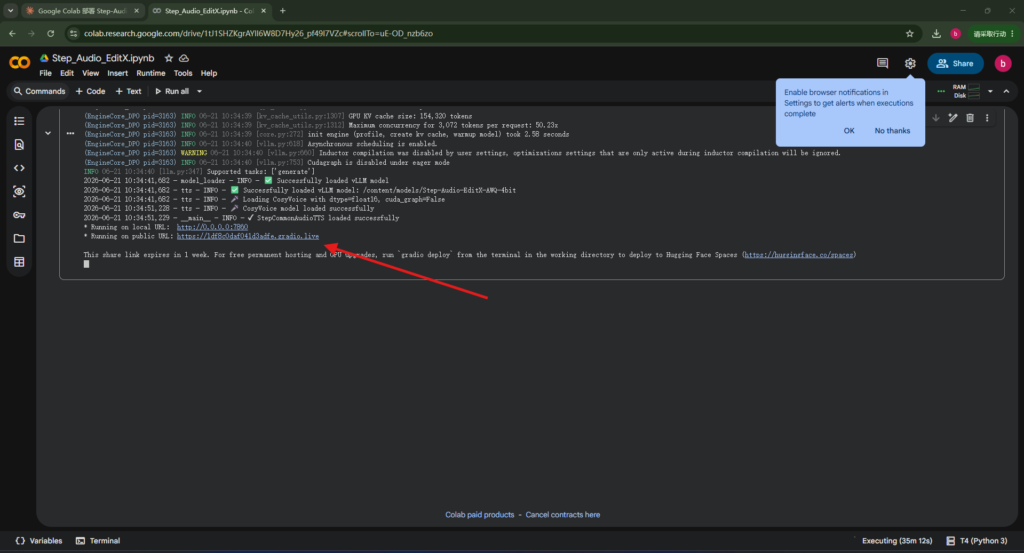
5、部署完成,并给出了访问链接
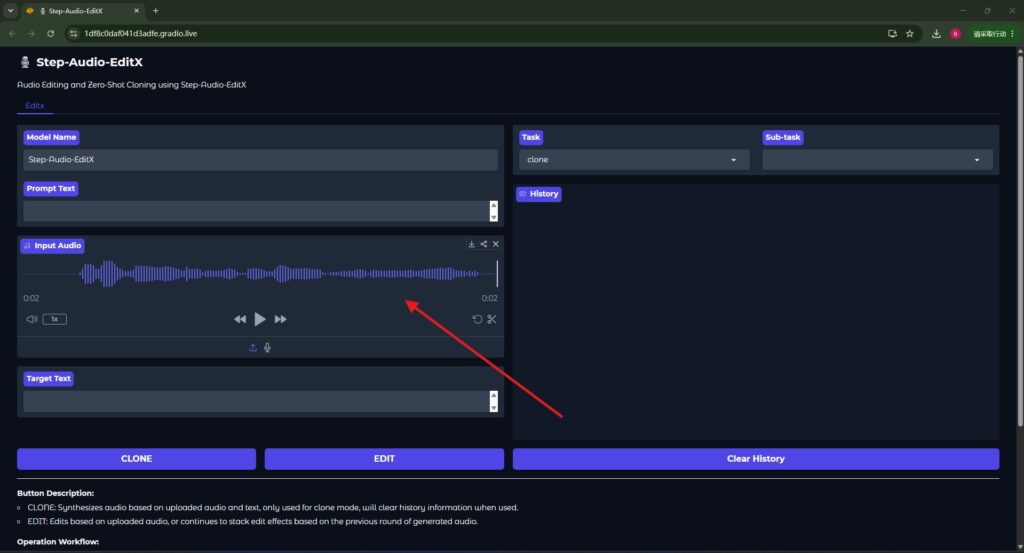
6、上传自己要复刻的声音然后点击CLONE,就可以生成你要的声音了。
最后,提供一个参考音频,可以到Google drive网盘下载。
声明:本教程仅用于个人技术学习、学术研究及娱乐体验,请勿将克隆后的声音用于任何商业盈利、非法诈骗或未授权的侵权活动。由此产生的一切法律后果由使用者自行承担。